Integration with Tidymodel: Tune and Friends
Source:vignettes/articles/integration_tidymodels.Rmd
integration_tidymodels.RmdThe most central aspect of tidy.outliers is to combine it on a workflow to filter outliers out of your training dataset, and to consider the outlier removal process just one of your many dials controlled hyper parameters, you can even ‘pool’ the score out of multiple outlier methods!
Create the recipe
ames_rec <-
recipe(Sale_Price ~ Gr_Liv_Area + Longitude + Latitude, data = ames_train) |>
step_log(Gr_Liv_Area, base = 10) |>
step_ns(Longitude, deg_free = tune("long df")) |>
step_ns(Latitude, deg_free = tune("lat df")) |>
step_outliers_maha(all_numeric(), -all_outcomes()) |>
step_outliers_lookout(all_numeric(),-contains(r"(.outliers)"),-all_outcomes()) |>
step_outliers_remove(contains(r"(.outliers)"),score_dropout = tune("dropout"),aggregation_function = tune("aggregation"))See the parameters
parameters(ames_rec)
#> Warning: `parameters.workflow()` was deprecated in tune 0.1.6.9003.
#> ℹ Please use `hardhat::extract_parameter_set_dials()` instead.
#> Collection of 4 parameters for tuning
#>
#> identifier type object
#> long df deg_free nparam[+]
#> lat df deg_free nparam[+]
#> dropout score_dropout nparam[+]
#> aggregation aggregation_function dparam[+]There is already a function for dropouts implemented by dials
ames_param <-
ames_rec |>
parameters() |>
update(
`long df` = spline_degree(),
`lat df` = spline_degree(),
dropout = dropout(range = c(0.75, 1)),
aggregation = aggregation() |> value_set(c("mean","weighted_mean"))
)Grid Search picks random points
spline_grid <- grid_max_entropy(ames_param, size = 20)
spline_grid
#> # A tibble: 20 × 4
#> `long df` `lat df` dropout aggregation
#> <int> <int> <dbl> <chr>
#> 1 10 5 0.893 mean
#> 2 6 10 0.793 weighted_mean
#> 3 5 8 0.890 mean
#> 4 4 6 0.969 mean
#> 5 3 6 0.778 mean
#> 6 2 4 0.974 weighted_mean
#> 7 5 6 0.785 weighted_mean
#> 8 1 1 1.00 weighted_mean
#> 9 7 8 0.773 mean
#> 10 5 3 0.870 weighted_mean
#> 11 6 3 0.792 weighted_mean
#> 12 10 3 0.968 weighted_mean
#> 13 6 7 0.973 mean
#> 14 3 2 0.940 mean
#> 15 8 6 0.864 weighted_mean
#> 16 10 4 0.761 weighted_mean
#> 17 10 2 0.831 weighted_mean
#> 18 7 10 0.948 weighted_mean
#> 19 8 1 0.990 mean
#> 20 1 10 0.765 weighted_meanCreate training folds
set.seed(2453)
cv_splits <- vfold_cv(ames_train, v = 5, strata = Sale_Price)Tune the grid
ames_res <- tune_grid(wf_tune, resamples = cv_splits, grid = spline_grid)
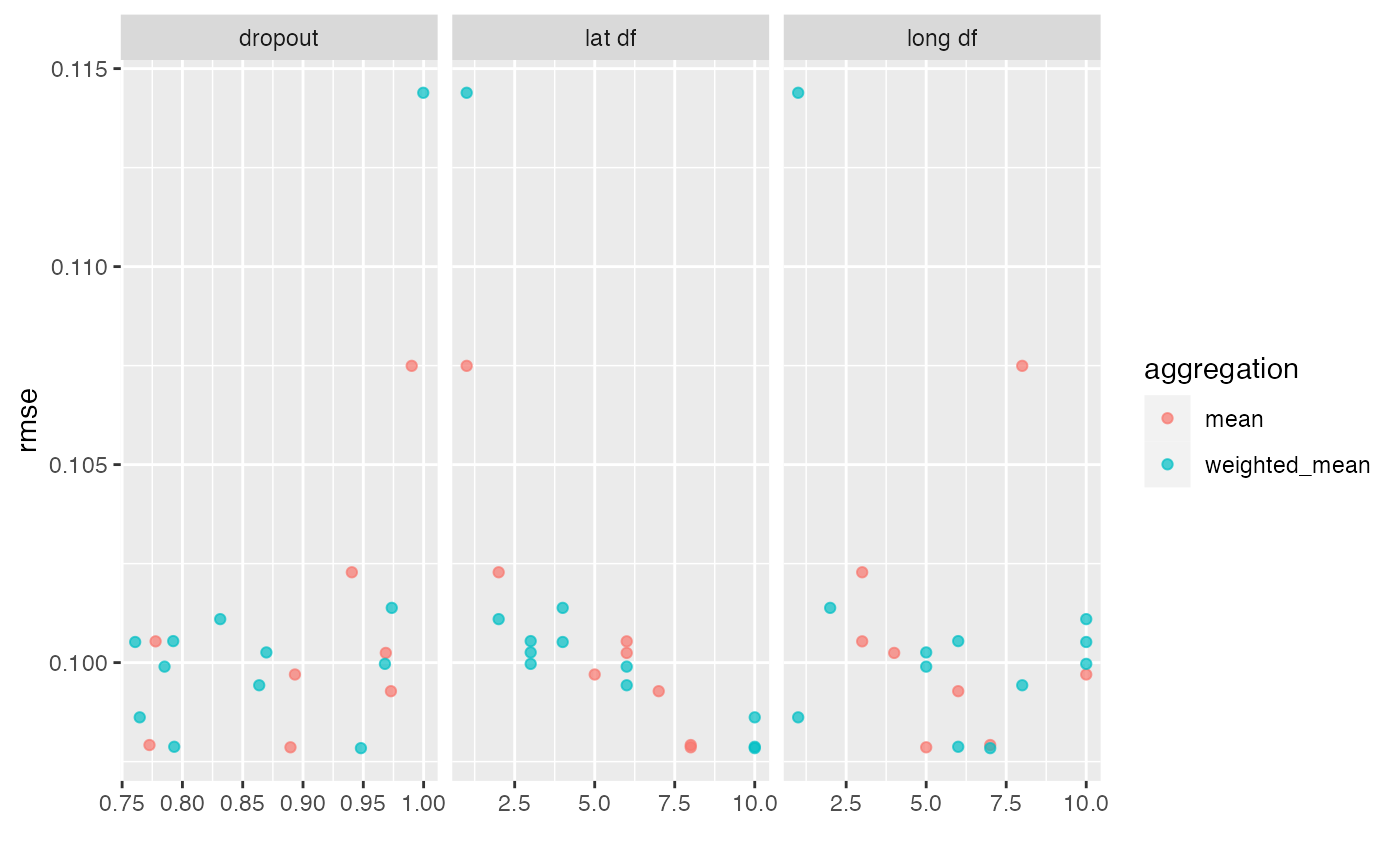
estimates <- collect_metrics(ames_res)
rmse_vals <-
estimates |>
dplyr::filter(.metric == "rmse") |>
arrange(mean)
rmse_vals
#> # A tibble: 20 × 10
#> long d…¹ lat d…² dropout aggre…³ .metric .esti…⁴ mean n std_err .config
#> <int> <int> <dbl> <chr> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 7 10 0.948 weight… rmse standa… 0.0978 5 0.00242 Prepro…
#> 2 5 8 0.890 mean rmse standa… 0.0979 5 0.00224 Prepro…
#> 3 6 10 0.793 weight… rmse standa… 0.0979 5 0.00242 Prepro…
#> 4 7 8 0.773 mean rmse standa… 0.0979 5 0.00231 Prepro…
#> 5 1 10 0.765 weight… rmse standa… 0.0986 5 0.00216 Prepro…
#> 6 6 7 0.973 mean rmse standa… 0.0993 5 0.00199 Prepro…
#> 7 8 6 0.864 weight… rmse standa… 0.0994 5 0.00177 Prepro…
#> 8 10 5 0.893 mean rmse standa… 0.0997 5 0.00183 Prepro…
#> 9 5 6 0.785 weight… rmse standa… 0.0999 5 0.00199 Prepro…
#> 10 10 3 0.968 weight… rmse standa… 0.100 5 0.00204 Prepro…
#> 11 4 6 0.969 mean rmse standa… 0.100 5 0.00184 Prepro…
#> 12 5 3 0.870 weight… rmse standa… 0.100 5 0.00217 Prepro…
#> 13 10 4 0.761 weight… rmse standa… 0.101 5 0.00220 Prepro…
#> 14 3 6 0.778 mean rmse standa… 0.101 5 0.00170 Prepro…
#> 15 6 3 0.792 weight… rmse standa… 0.101 5 0.00214 Prepro…
#> 16 10 2 0.831 weight… rmse standa… 0.101 5 0.00218 Prepro…
#> 17 2 4 0.974 weight… rmse standa… 0.101 5 0.00193 Prepro…
#> 18 3 2 0.940 mean rmse standa… 0.102 5 0.00206 Prepro…
#> 19 8 1 0.990 mean rmse standa… 0.107 5 0.00215 Prepro…
#> 20 1 1 1.00 weight… rmse standa… 0.114 5 0.00175 Prepro…
#> # … with abbreviated variable names ¹`long df`, ²`lat df`, ³aggregation,
#> # ⁴.estimator